
Every data project I have worked on eventually needs web data, and every time the same question comes up: do we scrape it, or is there a cleaner way? I spent most of 2025 building two tools that forced me to answer that question from both sides.
Ares is a web scraper. It fetches arbitrary pages — static HTML or JavaScript-rendered SPAs — converts them to Markdown, and asks an LLM to extract structured data according to a JSON Schema. Ceres is a harvester. It talks to CKAN open-data portals through their official APIs, generates semantic embeddings, and maintains a searchable index across a federation of public datasets.
I did not set out to build a contrast. But harvesting Ireland’s aggressively rate-limited portal, dealing with Swiss multilingual metadata, parsing Japanese characters from Tokyo’s open data, and running a monster 110,000-dataset sync against Australia — those experiences made the divide between scraping and harvesting very concrete, very fast.
Scraping vs harvesting: where I draw the line
When I started Ares, I called it “a scraper” without thinking much about the word. When I started Ceres, I instinctively called it “a harvester.” Only later did I realise the distinction was not just naming — it reflected fundamentally different relationships with the data source.
Scraping is a technique. You point a script at a page, extract what you need, and move on. The source does not know you exist, does not want you there, and will change its markup without warning. Your code is inherently fragile because the contract is one-sided: you are reading someone else’s UI, not consuming an API they designed for you.
Harvesting is what happens when the source cooperates. An open-data portal publishes a CKAN API specifically so that machines can consume its catalog. There is a schema, pagination, metadata timestamps, and often rate-limit headers telling you how fast you can go. The contract is two-sided, and your pipeline can be built around it.
Scraping is a technique; harvesting is the product and pipeline wrapped around that technique.
The practical consequence is that the same engineering patterns — retries, circuit breakers, job queues, change detection — show up in both, but the posture is different. A harvester collaborates with the source; a scraper works despite it. And in 2026, with tools like Scrapy, Playwright, Firecrawl, and managed providers like Apify and Zyte making the scraping infrastructure increasingly commoditised, the real differentiator is no longer “can you get the data” but “can you keep getting it reliably, at scale, without breaking things.”
That is what Ares and Ceres are about. One on each side of the line.
Ares: LLM-powered structured scraping
Ares is a web scraper with a very opinionated design around structured data extraction. Named after the Greek god of war — where Ceres tends the garden, Ares takes what it finds.
The project is a Rust workspace with five crates: ares-core (traits, domain models, service logic), ares-client (concrete implementations for HTTP, browser, LLM), ares-db (PostgreSQL persistence), ares-cli (the command-line interface), and ares-server (an Axum REST API). Every external dependency sits behind a trait — Fetcher, Cleaner, Extractor, ExtractionStore — making it straightforward to swap implementations and test with mocks.
The scraping pipeline
The core pipeline is four stages: fetch → clean → extract → hash.
| |
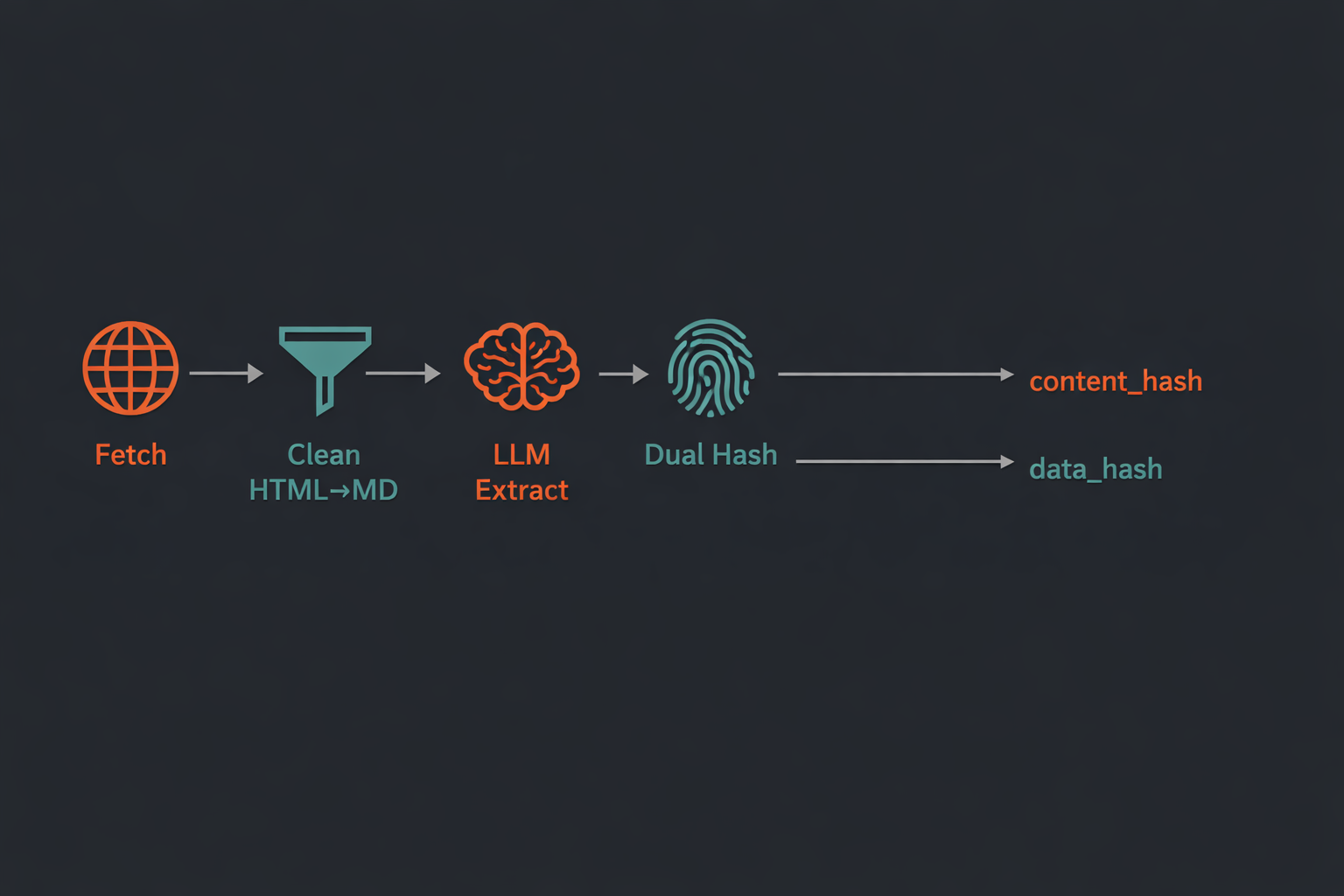
The dual-hash system is a deliberate design choice. content_hash tracks whether the page itself changed; data_hash tracks whether the structured extraction changed. This distinction matters: a page can change its layout, ads, or boilerplate while the LLM still extracts the same data — content_hash changes, data_hash stays the same. Conversely, if the underlying data genuinely changes, both hashes update. The pipeline uses data_hash comparison to determine whether downstream consumers should be notified.
The LLM extraction uses the OpenAI-compatible /chat/completions endpoint with response_format: { type: "json_schema" }. Despite the OpenAiExtractor name, it works with any compatible endpoint — OpenAI, Gemini (via the OpenAI compatibility layer), Ollama, vLLM, LiteLLM. You configure ARES_BASE_URL and ARES_MODEL and the same client handles the rest.
Fetching JavaScript-rendered pages
For static HTML, Ares uses a standard ReqwestFetcher. For SPAs and JS-heavy sites, it has a BrowserFetcher that drives a real Chromium instance via the Chrome DevTools Protocol. It is feature-gated — compile with --features browser to enable it.
One detail I am proud of: the browser binary auto-detection. On Ubuntu, Chromium is typically installed via Snap, and the Snap wrapper strips CLI flags like --headless that are essential for automation. Ares looks for the real binary buried inside the Snap package first:
| |
This is the kind of thing that only matters when you have actually tried to run headless Chromium on a real Linux system, and I spent a frustrating afternoon figuring it out.
Schema system
Schemas are versioned JSON Schema files organised in a directory with a small registry:
| |
You can reference them by path (schemas/blog/1.0.0.json), by version (blog@1.0.0), or by latest alias (blog@latest reads registry.json to resolve the current version). Promoting a new version to “latest” is a single edit to the registry file.
| |
From script to system
Where Ares really steps beyond a one-off script is in the production infrastructure around the core extraction.
Job queue. Scrape jobs are persisted in PostgreSQL with a full lifecycle: Pending → Running → Completed/Failed/Cancelled. You create jobs via CLI (ares job create) or via the REST API (POST /v1/jobs), then run ares worker to process them. The retry schedule is fixed at [1 minute, 5 minutes, 30 minutes, 1 hour]:
| |
I chose to hardcode the schedule rather than make it configurable per-job. In practice, most failure modes (LLM timeouts, rate limits, transient network issues) respond well to the same escalation pattern.
Circuit breaker. A three-state machine (Closed → Open → HalfOpen) protects against cascading failures when the LLM API goes down. The interesting part is the rate-limit-specific backoff: when the circuit opens due to HTTP 429 responses, the recovery timeout doubles (up to a 300-second cap), giving the upstream service more breathing room:
| |
Regular failures (network errors, 500s) use the base 30-second timeout. This distinction avoids treating all failures equally — a rate limit means “slow down,” not “the service is broken.”
Throttled fetching. ThrottledFetcher<F> is a composable wrapper that enforces per-domain minimum delays with configurable jitter. It is deliberately opt-in rather than automatic — if you are scraping a single page, you do not need throttling overhead, but for crawling workloads you wrap your fetcher and the throttle handles the rest. The jitter uses a lightweight xorshift64 PRNG to avoid pulling in the rand crate as a dependency.
Graceful shutdown. Workers use a CancellationToken. On Ctrl+C, the worker finishes the current job, releases any claimed jobs back to the queue (Pending status), and exits cleanly. Jobs are never lost.
REST API. ares-server exposes an Axum-based API with routes for job management (POST/GET/DELETE /v1/jobs) and extraction history (GET /v1/extractions), protected by API key authentication with constant-time comparison to prevent timing attacks. A public /health endpoint reports service and database status.
Ceres: harvesting open-data portals
Ceres is a semantic search engine for CKAN open-data portals. It harvests dataset metadata via official APIs, embeds it, and indexes it in PostgreSQL with pgvector — making public datasets discoverable by meaning rather than keyword. Named after the Roman goddess of harvest and grain.
The architecture mirrors Ares: five crates (ceres-core, ceres-client, ceres-db, ceres-cli, ceres-server), trait-based dependency injection, and PostgreSQL as the persistence layer.
The discoverability problem
A citizen searches for “air pollution” on a municipal portal and finds nothing — because the official dataset is called “PM10_monitoring_Q3_2024”. A researcher types “city population” and misses demographic data because it is tagged differently. The problem is not the amount of available data; it is that keyword search systematically fails when people do not know the administration’s taxonomy.
Ceres solves this by embedding dataset metadata (titles, descriptions, tags) into vector space and using cosine similarity for search. “Air pollution” finds PM10 monitoring data because the concepts are semantically close, even though the words never match.
Three sync modes
This is the most important architectural decision in Ceres, and one that directly affects API costs and portal load. The SyncPlan enum defines three strategies:
| |
Full fetches the list of dataset IDs, then retrieves each one individually — N+1 API calls for N datasets. This is the safe fallback.
FullBulk uses CKAN’s package_search with pagination (rows=1000) to pre-fetch all datasets in bulk. For a portal with 10,000 datasets, that is roughly 10 API calls instead of 10,001. This is the preferred strategy for large portals.
Incremental uses a Solr filter query (metadata_modified:[{last_sync} TO *]) to fetch only datasets that changed since the last successful sync. For steady-state operations, this reduces API calls by orders of magnitude.
A critical correctness detail: cancelled syncs do not advance last_successful_sync. If you cancel a harvest halfway through, the next incremental sync starts from the last fully completed checkpoint, ensuring no datasets fall through the cracks.
Lessons from real portals
These sync modes were not designed in the abstract — they emerged from hitting real portals.
Ireland has one of the most aggressively rate-limited CKAN instances I have encountered. The layered retry system in Ceres (per-request exponential backoff, per-page cooldowns, and a circuit breaker on top) was largely shaped by trying to harvest Irish data without getting permanently blocked. FullBulk mode was essential here — the ID-by-ID Full strategy would have triggered rate limits on every other request.
Switzerland exposed a different problem: multilingual metadata fields. A CKAN dataset can have its title as a plain string ("Air quality data") or as a JSON object ({"en": "Air quality data", "de": "Luftqualitätsdaten", "fr": "Données sur la qualité de l'air"}). Ceres handles both via a custom deserializer that resolves the preferred language, falls back to English, then to the first non-empty value. The content hash includes the language code, so switching your language preference triggers a full re-embedding — the right behaviour, since the semantic content is genuinely different.
Tokyo was where Unicode handling got serious. Japanese characters in dataset titles and descriptions flowed through the pipeline without issues (Rust’s native UTF-8 strings help enormously here), but it was a good stress test for the embedding models — semantic search across languages is a harder problem than within a single language.
Australia (data.gov.au) was the monster harvest: over 100,000 datasets. This is where FullBulk proved its worth most dramatically — roughly 100 paginated API calls instead of 100,001 individual fetches. The incremental mode then keeps it current with minimal load. Without these optimisations, harvesting Australia would have been impractical.
Embedding providers
As of v0.2.2, Ceres supports both Gemini and OpenAI embeddings, selected at runtime via the EMBEDDING_PROVIDER environment variable.
| |
The Gemini client uses gemini-embedding-001 with output_dimensionality: 768 — this is Matryoshka Representation Learning, where the model produces a truncated embedding at a lower dimension without retraining. The result is a 4× storage reduction compared to the native 3072 dimensions, with minimal quality loss for retrieval tasks.
A safety measure I added early: dimension enforcement at startup. Ceres checks that the configured embedding dimension matches the pgvector column in the database. If you switch from Gemini (768d) to OpenAI (1536d) without re-indexing, the startup check fails loudly rather than silently producing garbage similarity scores.
The provider trait uses return-position impl Trait (RPITIT), which is not object-safe in current Rust. Instead of Box<dyn EmbeddingProvider>, Ceres uses a concrete EmbeddingProviderEnum for runtime dispatch — a pragmatic workaround until the language evolves.
Delta detection
The DeltaDetector trait decides whether a dataset needs reprocessing:
| |
The default ContentHashDetector compares SHA-256 hashes — if the content has not changed, the embedding is not regenerated. On incremental runs against stable portals, nearly all datasets are unchanged, which is where the “up to 99.8% API cost savings” comes from. The hash input includes the language code, so a dataset whose English title changed but whose Italian title did not will still trigger reprocessing in the English-language context.
For full rebuilds — say, when you switch embedding models — AlwaysReprocessDetector is a first-class escape hatch that re-embeds everything regardless of hash state.
Dry-run mode
Before committing to a potentially expensive full harvest, you can run in dry-run mode: datasets are fetched, hashes computed, and delta detection runs, but no embeddings are generated and no database writes occur. This lets you estimate what the harvest would do — how many new datasets, how many updates, how many unchanged — before spending a single API credit.
Parquet export
Ceres can export its entire index to Parquet files (Arrow-backed, Zstd-compressed) for downstream consumption — uploading to Hugging Face, feeding into Databricks, or any columnar workflow. The export includes cross-portal duplicate detection: datasets appearing in multiple portals are marked with an is_duplicate boolean rather than silently removed, preserving transparency about what data exists where. A noise filter strips records with titles shorter than 5 characters or matching placeholder patterns.
Where Ceres and Ares fit together
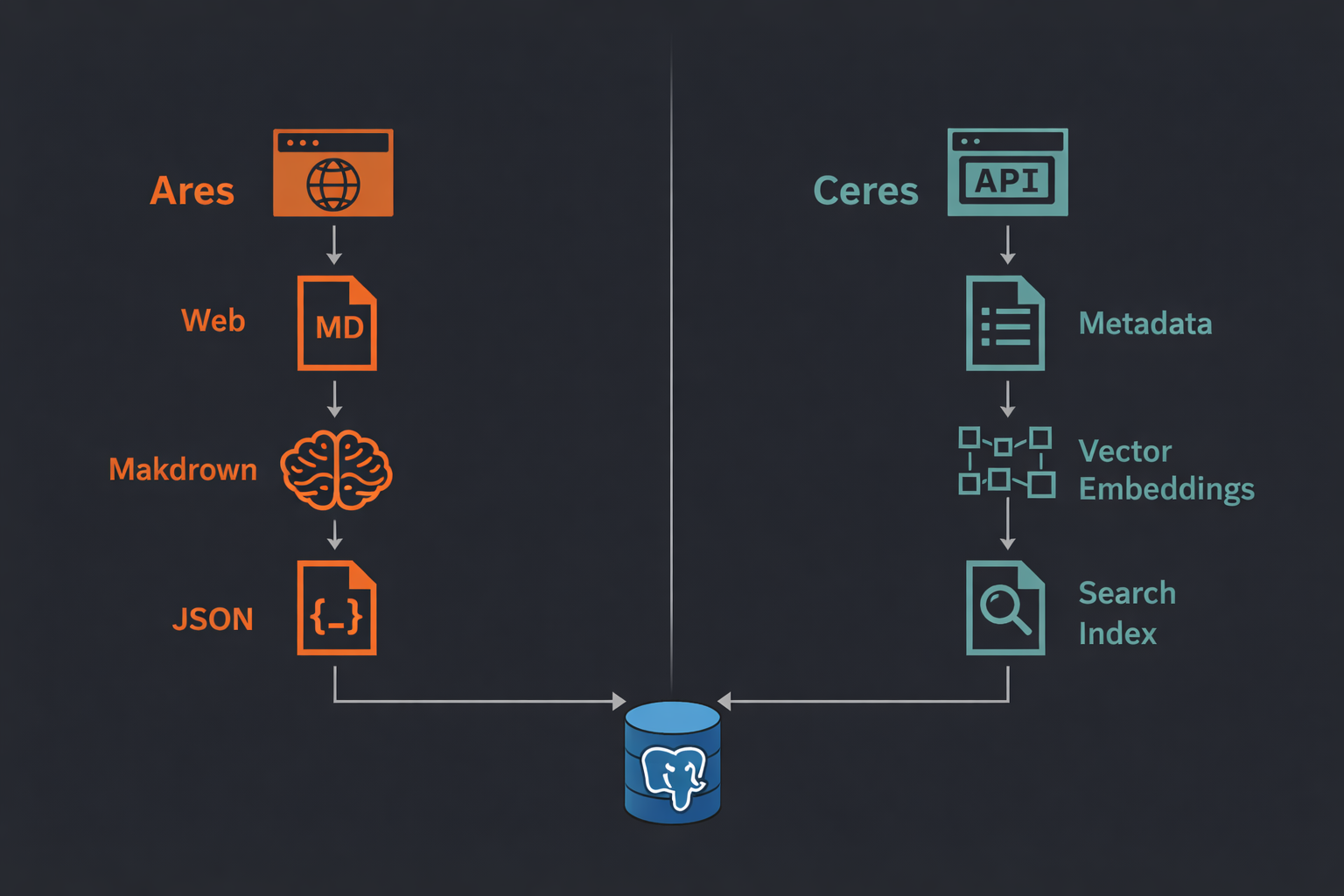
Ceres and Ares share the same crate architecture (*-core, *-client, *-db, *-server, *-cli), the same PostgreSQL backing, the same circuit breaker pattern, and the same trait-based dependency injection. Yet their temperaments are completely different.
Ceres operates in collaboration with data publishers. It uses official CKAN APIs, respects portal rate limits through layered retry and circuit breaking, and its index gets richer over time as more portals are added. The relationship with the source is cooperative.
Ares is adversarial in the engineering sense. It must deal with arbitrary HTML, JavaScript-rendered SPAs, rate limiting from sites that may not welcome scraping, and the inherent noise of extracting structure from unstructured content via an LLM. The relationship with the source is opportunistic.
| Dimension | Scraping (Ares) | Harvesting (Ceres) |
|---|---|---|
| Source interface | Arbitrary HTML/JS | Official CKAN API |
| Extraction method | LLM + JSON Schema | Structured metadata + embeddings |
| Change detection | content_hash + data_hash | ContentHashDetector with SHA-256 |
| API efficiency | 1 call per URL | FullBulk: ~N/1000 calls |
| Output | Typed JSON documents | Semantic vector index (pgvector) |
Together they illustrate a principle: when sources offer stable APIs and data contracts, build harvesters. When you must go through the HTML, build scrapers — but give them the same production discipline. Schemas, job queues, workers, retries, circuit breakers, and graceful shutdown are not optional extras. They are what separate a useful tool from a script that works until it doesn’t.
What I learned
Building Ares and Ceres back-to-back made the harvesting-vs-scraping distinction concrete in a way that reading about it never did. Scraping is the technique; harvesting is what you build when the technique needs to run in production every day, reliably, with SLAs and observability.
The Rust ecosystem makes this kind of pipeline surprisingly tractable. Tokio for async, sqlx for database access, pgvector for similarity search, Axum for HTTP APIs — they compose well, and the type system catches categories of bugs that would be runtime surprises in dynamic languages. The hardest parts were not technical: they were deciding what belongs in *-core versus *-client, and resisting the urge to over-engineer before there was evidence of a real requirement.
Both projects are under active development. Ares has a crawling mode (link discovery from extractions) on the roadmap. Ceres has Socrata and DCAT portal types stubbed out in the codebase, waiting for implementation. If either of these resonates with what you are building, the repos are open — contributions are welcome.