
Introduction
In the world of modern robotics, data is the new oil. But unlike oil, robotics data is extraordinarily complex: high-frequency sensor streams, LiDAR point clouds, compressed video flows, real-time telemetry, and outputs from perception algorithms that generate terabytes of information every single day of operation.
I discovered Mosaico purely by chance while browsing around. The project, born in 2025 at Mosaico Labs, was recently made open-source and represents an innovative approach to the problem: a data platform designed specifically for Robotics and Physical AI, featuring a high-performance Rust backend and a Python SDK that integrates natively with ROS 2.
What struck me immediately was the architectural vision. The founding team, with experience in Autonomous Driving at companies like Ambarella, built Mosaico starting from real-world problems: How do you debug a robotic system when the bug only manifests after hours of operation? How do you search for specific patterns in petabytes of sensory data? How do you guarantee data certifiability for industrial standards like ISO 26262?
After studying the codebase and actively contributing to the project with several pull requests and discussion proposals, I want to share what makes Mosaico interesting and why it represents a fascinating case study of Rust + Python integration in the data domain.
The Problem: Robotics Data ≠ IT Data
Before diving into Mosaico’s architecture, it is crucial to understand why robotics data requires different treatment compared to traditional IT data.
Unique Characteristics of Robotics Data
High Frequency and Synchronization: A modern robot can generate data from dozens of sensors simultaneously. A stereo camera produces 60 frames per second, a LiDAR 10-20 scans per second, and an IMU (Inertial Measurement Unit) up to 1000 samples per second. All these streams must be temporally synchronized with sub-millisecond precision to correctly reconstruct the system state.
Massive Binary Data Volumes: Robotics data is predominantly binary and high-density. A single Velodyne LiDAR generates about 300 MB of point clouds per minute. A fleet of 100 operational robots can produce petabytes of data in just a few months.
Heterogeneity of Formats: ROS bag files, serialized protobufs, proprietary sensor formats, H.264/H.265 video, PLY or PCD point clouds. Every component of the robotic system has its own serialization conventions.
Perfect Reconstruction Requirements: Unlike traditional analytics where aggregation and sampling are acceptable, robotics debugging requires the exact reconstruction of the system state at any given instant. A bug causing a collision might depend on a single anomalous frame in a stream of millions.
Limitations of Traditional Approaches
Generic Data Lakes: Solutions like Apache Iceberg or Delta Lake excel at tabular analytics but are not designed for high-frequency sensory streams. They lack primitives for time synchronization, deterministic replay, and semantic search on unstructured data.
Visualization Tools: Tools like Foxglove or RViz are excellent for visualizing robotics data in real-time, but they do not solve the problem of organized storage, governance, and search over historical datasets.
Time-Series Databases: InfluxDB, TimescaleDB, and similar handle numerical metrics well, but they are not optimized for massive binary blobs like point clouds or images.
Traditional ETL Pipelines: Tools like Apache Spark or Flink are designed for batch processing or discrete event streaming, not for the deterministic reconstruction of continuous sensory streams.
The Gap to Bridge
Mosaico was born to bridge this gap: a platform that combines the capabilities of a modern data lake (scalable storage, metadata management, governance) with robotics-specific primitives (time synchronization, deterministic replay, semantic search on sensory data).
Mosaico Architecture
Mosaico’s architecture follows a client-server pattern that clearly separates responsibilities between a high-performance Rust daemon and a Python SDK designed for developer ergonomics.
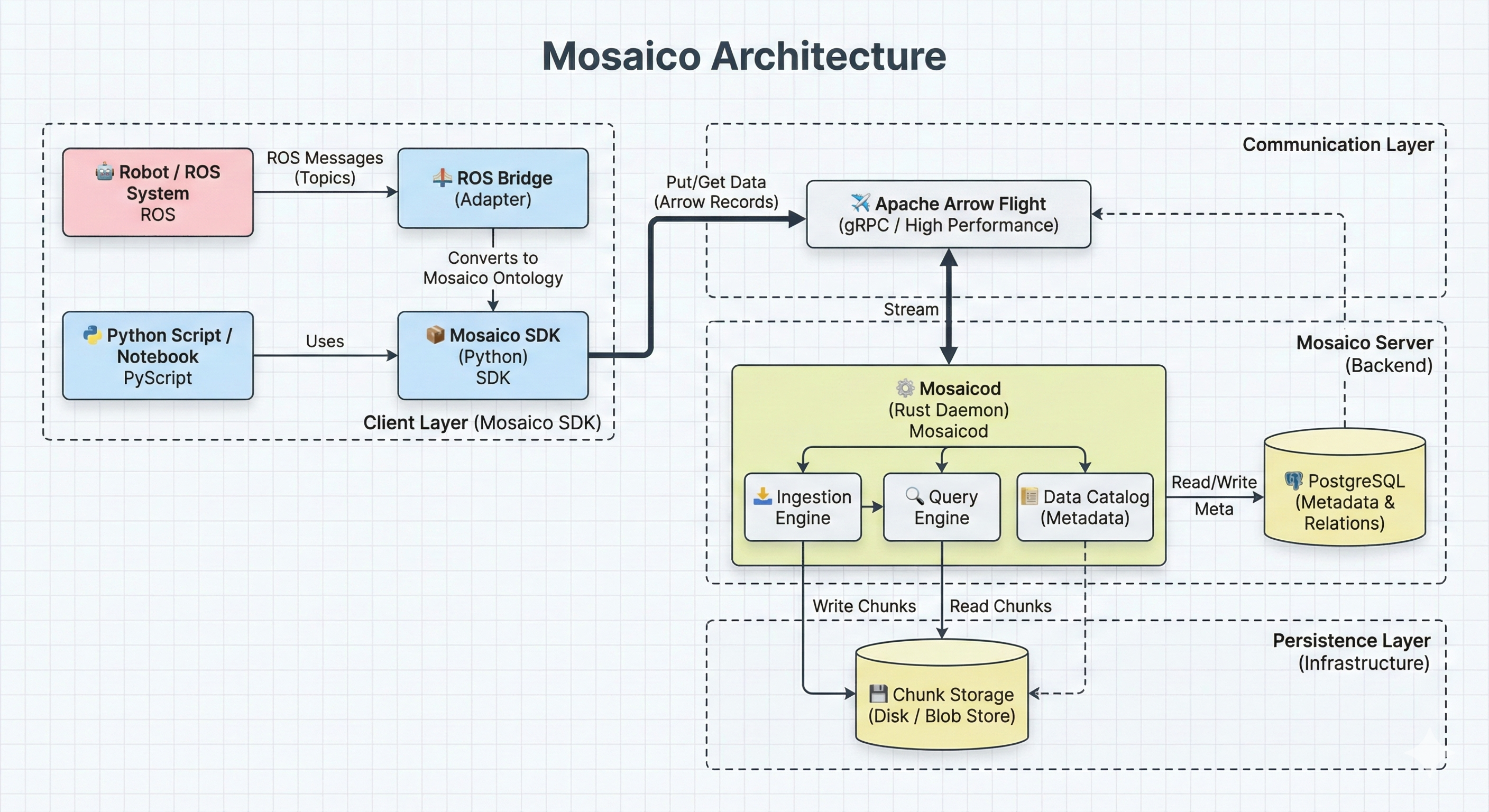 Schema of Mosaico’s client-server architecture: the Rust daemon (mosaicod) handles storage, compression, and metadata, while Python clients communicate via Apache Arrow Flight.
Schema of Mosaico’s client-server architecture: the Rust daemon (mosaicod) handles storage, compression, and metadata, while Python clients communicate via Apache Arrow Flight.
mosaicod: The Rust Daemon
The heart of Mosaico is mosaicod, a daemon written entirely in Rust that handles all heavy operations:
Storage and Compression: mosaicod receives data from clients, applies compression optimized for the data type (different codecs for images, point clouds, telemetry), and organizes storage efficiently.
Metadata Management: It uses PostgreSQL as a metadata backend, with SQL queries verified at compile-time via sqlx. This guarantees end-to-end type safety: if a query is malformed, the Rust compiler rejects it before the code even runs.
Semantic Indexing: mosaicod automatically extracts semantic metadata from raw data (GPS coordinates, timestamps, classifications) and indexes them for efficient searches.
Protocol Server: It exposes an interface based on Apache Arrow Flight for high-performance communication with clients.
| |
Python SDK: Ergonomics and Integration
The Python SDK (mosaico-sdk-py) provides a clean interface for interacting with mosaicod:
Communication Abstraction: The SDK hides the complexity of the Arrow Flight protocol, exposing Pythonic APIs for reading and writing.
ROS 2 Integration: Native converters for the most common ROS 2 message types, allowing sequences to be loaded directly from ROS topics.
Ecosystem Compatibility: Interoperability with PyArrow, NumPy, and ML frameworks like PyTorch and TensorFlow.
The following example illustrates a query to the platform and shows how to download data from one of the returned sequences, as well as how to obtain a synchronized data stream:
| |
The SDK automatically executes a k-way merge sort on the client side to ensure sensor messages are returned in the correct temporal order. The data stream is not downloaded all at once, but via an intelligent buffering strategy using memory-limited batches, which are automatically replaced by new batches as data is processed.
The Three Pillars: Ontology, Topic, Sequence
Mosaico’s architecture relies on three fundamental concepts that structure data organization:
Ontology: The semantic representation of data types. The ontology defines what each sensor type, detection, or semantic map means. It is not just a validation schema, but a shared vocabulary that enables cross-dataset searches.
Topic: A Topic represents a specific data source (e.g., “front_camera”, “lidar_top”, “gps_position”) with its associated ontology and storage configuration.
Sequence: A Sequence is a collection of logically related Topics. For example, a robot recording session, like a ROS bag, is a Sequence containing readings from various sensors, where each sensor (like Lidar, GPS, or accelerometer) is represented by a Topic.
Value Proposition: Beyond Storage
Mosaico is not just a storage system. Its architecture enables capabilities that go far beyond simply saving data.
Data-Oriented Debugging
Traditional debugging in robotics relies on textual logs and real-time visualization. When a robot fails a mission, engineers have to mentally reconstruct what happened by analyzing fragmented logs.
In the project’s roadmap, one of the most significant future developments concerns the introduction of data-oriented debugging, a fundamental feature for improving the development process of robotic algorithms:
- Complete Checkpoints: Instead of logging only significant events, Mosaico will allow saving the full state of every pipeline component at regular intervals: sensor preprocessing, estimation filter outputs, intermediate algorithm checkpoints—everything is preserved.
- Deterministic Replay: With all intermediate states saved, it will be possible to “rewind” the robot’s execution to any point in time and inspect the exact state of the system.
- Root Cause Analysis: When an anomaly is identified (e.g., an incorrect detection), one can trace backward through the pipeline to identify the exact point where the error originated: was it the sensor, the preprocessing, or the detection algorithm?
Already in version v0.1, it is possible to extract the data stream of a sequence or a single topic, optionally specifying time intervals of interest. This approach minimizes the amount of data exchanged, avoiding the transfer of superfluous information:
| |
Semantic Data Platform
Mosaico’s ontology is not just a validation schema—it is a semantic infrastructure that enables intelligent operations on data.
Cross-Team Standardization: In organizations with multiple robotics teams, the ontology provides a common vocabulary. A “pedestrian_detection” means the same thing for the perception team and the planning team.
Automatic Metadata Extraction: Mosaico automatically extracts semantic metadata from raw data. GPS coordinates are indexed for geospatial searches, timestamps for temporal queries, and classifications for categorical searches.
Storage Optimization by Type: The ontology maps each data type to the optimal storage format. Point clouds use specialized compression, images use video codecs, and numerical telemetry uses columnar formats.
Data Model Versioning: The ontology supports versioned evolution. When a sensor format changes, the new version coexists with the old one, allowing queries that span both.
Roadmap: Multimodal Search
With petabytes of robotics data, finding specific information becomes impossible with traditional approaches based on filenames or manual tags.
Mosaico enables multimodal search on temporal data and metadata (relative to sequences and topics). The development team is designing increasingly complex and efficient search architectures that will allow geospatial, embedding-based, and natural language queries, such as: «Find all sequences where the robot attempted to grasp a red apple».
Certifiability
For industrial applications (automotive, aerospace, medical), data must meet rigorous certification standards. A strategic component of the project roadmap is dedicated to the certifiability of algorithmic pipelines, which will be progressively extended to cover the entire data lifecycle.
Full Data Lineage (Evolving): Mosaico is designed to exhaustively track the provenance of every piece of data—sensor, firmware version, preprocessing algorithm—with the goal of offering complete and verifiable traceability.
Declarative Validation (In Development): Quality rules can be defined at the ontology level and automatically validated during the data ingestion phase.
Audit Trail (Roadmap): Every operation on data will be logged to ensure compliance with industry standards such as ISO 26262 (automotive), EASA (aerospace), and MISRA.
Why Rust + Python (Not FFI)
One of Mosaico’s most interesting architectural choices is the use of a client-server pattern instead of the more common FFI (Foreign Function Interface) bindings via PyO3 or Maturin.
The Traditional Pattern: PyO3/FFI
The most common approach to integrating Rust and Python is to compile Rust code as a native library and expose it to Python via PyO3:
| |
This works well for stateless and CPU-bound operations but has limitations for complex data platforms.
Why Mosaico Chose Client-Server
Process Isolation: With a separate daemon, crashes in the Rust backend do not terminate the Python application. This is critical for robotic systems where stability is paramount.
Multi-Tenancy: A single mosaicod daemon can serve multiple Python clients simultaneously, sharing resources (connection pools, cache, indices) efficiently.
Containerization: The client-server architecture integrates naturally with containerized deployments. The daemon can run in a dedicated container with isolated resources, while Python clients live in separate containers.
Independent Scaling: Backend and clients can scale independently. You can have a mosaicod daemon on powerful hardware serving dozens of lightweight clients.
Language Flexibility: With a well-defined protocol (Arrow Flight), it is easy to add clients in other languages (Go, C++, native Rust) without modifying the backend.
Team Scaling: Rust specialists focus on the high-performance backend, while Python specialists focus on the SDK and integrations. Teams can work in parallel with clear interfaces.
Evolution: The backend can evolve internally (new compression algorithms, storage optimizations) without breaking compatibility with existing clients, as long as the protocol remains stable.
Trade-offs
This architecture is not without costs:
Network Latency: Every call traverses the network stack, adding ~0.5-1ms of overhead compared to direct FFI calls (~microseconds).
Operational Complexity: You need to manage an extra daemon, with its own lifecycle, monitoring, and configuration.
Serialization: Data must be serialized/deserialized to cross the process boundary, consuming CPU.
For Mosaico, these trade-offs are acceptable because typical operations (writing sensory sequences, querying datasets) are already in the order of tens/hundreds of milliseconds, making network overhead negligible.
My Contribution to the Project
My journey with Mosaico started as it often does in open source: with documentation. Broken links, inconsistent instructions—nothing dramatic, but the kind of low-impact improvement that is always welcome in Open Source. From there, over the last three weeks, my involvement grew naturally through PRs, issues, discussions, and RFCs.
Among my most significant contributions: issue #18, where I identified a serious performance problem in calculating optimal batch size—O(N) sequential HEAD requests to S3, ~50 seconds wait with 1,000 chunks. The solution? A single O(1) SQL query. And PR #40, born from a discussion in issue #27: how to allow clients to discover available topics? I proposed the Arrow Flight convention—an empty path returns the full list—and then implemented the endpoint. My first “real” feature.
But the anecdote that best tells the experience is PR #52. It was 10 PM, I was analyzing SequenceTopicGroups::merge and noticed an O(n×m) complexity that could become O(n+m) with a HashMap. I wrote the benchmarks, opened the PR, and the maintainer replied with a point I hadn’t considered: for small datasets (< 100 sequences), linear search can beat the HashMap thanks to cache locality. A genuine technical discussion ensued—sort + binary search as a compromise, crossover point around 50-100 elements. The PR is still open and I myself took a step back on the implementation, but we will keep trying! There is no true failure in programming, only the failure not to try. It is exactly this kind of exchange that makes open source stimulating: you are not just writing code, you are learning.
Currently, I am pushing forward an RFC (issue #45) for integration with Data Contract Engine—defining explicit contracts on data and validating them during ingestion. The proposal has generated interest, and we’ll see where it leads.
Reviews in 24-48 hours, constructive comments, openness to architectural proposals. For those who want to start: documentation, ergonomics, small fixes. Not because they are “minor” contributions, but because they allow you to understand the codebase and build the confidence for more ambitious proposals.
Competitive Landscape
Mosaico does not operate in a vacuum. Other tools exist that address parts of the robotics data problem.
Foxglove
Focus: Real-time visualization and observability.
Strengths: Excellent multimodal visualization, support for ROS bags, modern web interface, efficient streaming.
Limitations vs. Mosaico: Foxglove is primarily a visualization tool, not a storage and governance platform. It does not offer primitives for data-oriented debugging on historical datasets or semantic search over petabytes.
Rerun
Focus: Multimodal data stack for ML and robotics.
Strengths: Elegant SDK, optimized for ML workflows, support for various data types (point clouds, tensors, images).
Limitations vs. Mosaico: Rerun focuses on visualization and logging for development. It lacks enterprise capabilities for governance, certifiability, and petabyte-scale storage.
ARES
Focus: Robot evaluation via annotation and curation.
Strengths: Structured workflows for data annotation, robot evaluation metrics, integration with ML pipelines.
Limitations vs. Mosaico: ARES is focused on the evaluation/annotation phase, not the entire data lifecycle from collection to debugging.
Mosaico Differentiators
| Aspect | Mosaico | Foxglove | Rerun | ARES |
|---|---|---|---|---|
| Petabyte-scale storage | ✅ | ❌ | ❌ | ❌ |
| Data-oriented debugging | ✅ | Partial | ❌ | ❌ |
| Semantic Ontology | ✅ | ❌ | Partial | ❌ |
| Certifiability | ✅ | ❌ | ❌ | ❌ |
| Real-time Visualization | Partial | ✅ | ✅ | ✅ |
| ROS 2 integration | ✅ | ✅ | ✅ | ✅ |
Mosaico does not compete directly with these tools—it can integrate with them. Data managed by Mosaico can be visualized in Foxglove, sequences can feed Rerun pipelines for development, and curated datasets can be exported to ARES for annotation.
Getting Started with Mosaico
If you want to try Mosaico, the easiest way is using Docker Compose.
Quickstart with Docker
| |
This starts:
mosaicod: The Rust daemon on port 50051 (Arrow Flight)- PostgreSQL: Metadata backend
- (Optional) MinIO: S3-compatible object storage for data
First Use with Python SDK
| |
Example: Ingestion from ROS 2
The following example shows how to upload a native ROS 2 sequence (.db3 format) to Mosaico, using the ros-bridge provided by the library:
| |
Documentation and Resources
- Repository: https://github.com/mosaico-labs/mosaico
- Core Concepts:
CORE_CONCEPTS.mdin the repository explains the three pillars (Ontology, Topic, Sequence) - Python SDK: The
mosaico-sdk-py/directory contains examples and API documentation - mosaicod: The
mosaicod/directory contains the Rust daemon documentation
Conclusion
Mosaico represents an innovative approach to the robotics data problem. Instead of adapting generic data engineering tools, the project starts from the specific needs of robotics: time synchronization, deterministic replay, post-mission debugging, and certifiability.
The Rust + Python architecture with a client-server pattern is a pragmatic choice balancing performance, isolation, and ergonomics. The Rust daemon handles heavy operations with memory safety guarantees, while the Python SDK offers seamless integration with the ROS 2 and ML ecosystems.
The project is still young—open-sourced in December 2025—but has already demonstrated significant momentum. My contribution experience has been positive: the team is open to proposals, the review process is constructive, and there is room for both incremental contributions (fixes, optimizations) and architectural ones (like my RFC on Data Contracts).
For those working in the robotics or Physical AI domain who find themselves managing growing volumes of sensory data, Mosaico deserves attention. It does not replace existing visualization tools but complements them by providing the storage, governance, and debugging infrastructure missing in the current ecosystem.
Call to Action
If you are interested in contributing, here are some areas where the project needs help:
Specialized Ontologies: Defining ontologies for new sensor types or application domains (agricultural robots, underwater vehicles, humanoids).
Integration Testing: More coverage for edge case scenarios and integration with different ROS 2 setups.
Documentation: Practical guides, tutorials, and usage case studies.
Alternative Client SDKs: Implementations in Go, C++, or native Rust for environments where Python is not available.
The future of robotics is data-driven. Tools like Mosaico are fundamental to transforming petabytes of sensory data from dead weight into a strategic resource for debugging, training, and continuous improvement of robotic systems.
Repository: https://github.com/mosaico-labs/mosaico
My Contributions:
- PR #56, #51, #40, #37, #33, #26, #23, #20, #15
- RFC #45: Data Contract Validation
- Issue #18, #27 and various discussions
Code snippets kindly curated by Francesco Di Corato, CSO@ Mosaico
A thank you to the Mosaico Labs team for the welcome, constructive reviews, and willingness to discuss architectural proposals. Open source works when there is openness towards contributors—and here I found it.