
Ogni progetto dati su cui ho lavorato, prima o poi, ha bisogno di dati dal web, e ogni volta torna la stessa domanda: facciamo scraping, oppure c’è un modo più pulito? Ho passato gran parte del 2025 a costruire due strumenti che mi hanno costretto a rispondere a questa domanda da entrambi i lati.
Ares è uno scraper web. Recupera pagine arbitrarie — HTML statico o SPA renderizzate in JavaScript — le converte in Markdown e chiede a un LLM di estrarre dati strutturati secondo uno JSON Schema. Ceres è un harvester. Dialoga con i portali open-data CKAN tramite API ufficiali, genera embedding semantici e mantiene un indice ricercabile su una federazione di dataset pubblici.
Non avevo pianificato di costruire un confronto. Ma harvestare il portale irlandese con rate limit molto aggressivi, gestire metadati multilingua svizzeri, parsare caratteri giapponesi dagli open data di Tokyo e lanciare una sync gigantesca da 110.000 dataset in Australia — queste esperienze hanno reso la differenza tra scraping e harvesting molto concreta, molto in fretta.
Scraping vs harvesting: dove traccio il confine
Quando ho iniziato Ares, l’ho chiamato “scraper” senza pensarci troppo. Quando ho iniziato Ceres, invece, l’ho chiamato istintivamente “harvester”. Solo dopo ho capito che la differenza non era solo una questione di nome — rifletteva relazioni radicalmente diverse con la sorgente dati.
Lo scraping è una tecnica. Punti uno script su una pagina, estrai quello che ti serve e vai avanti. La sorgente non sa che esisti, non ti vuole lì e cambierà il markup senza preavviso. Il tuo codice è intrinsecamente fragile perché il contratto è unilaterale: stai leggendo la UI di qualcun altro, non consumando un’API progettata per te.
L’harvesting è ciò che succede quando la sorgente collabora. Un portale open data pubblica una API CKAN proprio perché le macchine possano consumare il catalogo. C’è uno schema, c’è la paginazione, ci sono timestamp nei metadati e spesso header di rate limit che ti dicono quanto velocemente puoi andare. Il contratto è bilaterale, e la pipeline può essere progettata attorno a quel contratto.
Lo scraping è una tecnica; l’harvesting è il prodotto e la pipeline costruiti attorno a quella tecnica.
La conseguenza pratica è che gli stessi pattern ingegneristici — retry, circuit breaker, job queue, change detection — compaiono in entrambi, ma cambia l’atteggiamento. Un harvester collabora con la sorgente; uno scraper lavora nonostante la sorgente. E nel 2026, con strumenti come Scrapy, Playwright, Firecrawl e provider gestiti come Apify e Zyte che rendono l’infrastruttura di scraping sempre più commoditizzata, il vero differenziatore non è più “riesci a prendere il dato?” ma “riesci a continuare a prenderlo in modo affidabile, a scala, senza rompere nulla?”.
È esattamente questo il senso di Ares e Ceres. Uno per ciascun lato del confine.
Ares: scraping strutturato con LLM
Ares è uno scraper web con un design molto opinionated attorno all’estrazione di dati strutturati. Prende il nome dal dio greco della guerra — dove Ceres coltiva il giardino, Ares prende ciò che trova.
Il progetto è una workspace Rust con cinque crate: ares-core (trait, modelli di dominio, logica di servizio), ares-client (implementazioni concrete per HTTP, browser, LLM), ares-db (persistenza PostgreSQL), ares-cli (interfaccia a riga di comando) e ares-server (API REST con Axum). Ogni dipendenza esterna è dietro una trait — Fetcher, Cleaner, Extractor, ExtractionStore — quindi è semplice sostituire implementazioni e testare con mock.
La pipeline di scraping
La pipeline core ha quattro stadi: fetch → clean → extract → hash.
| |
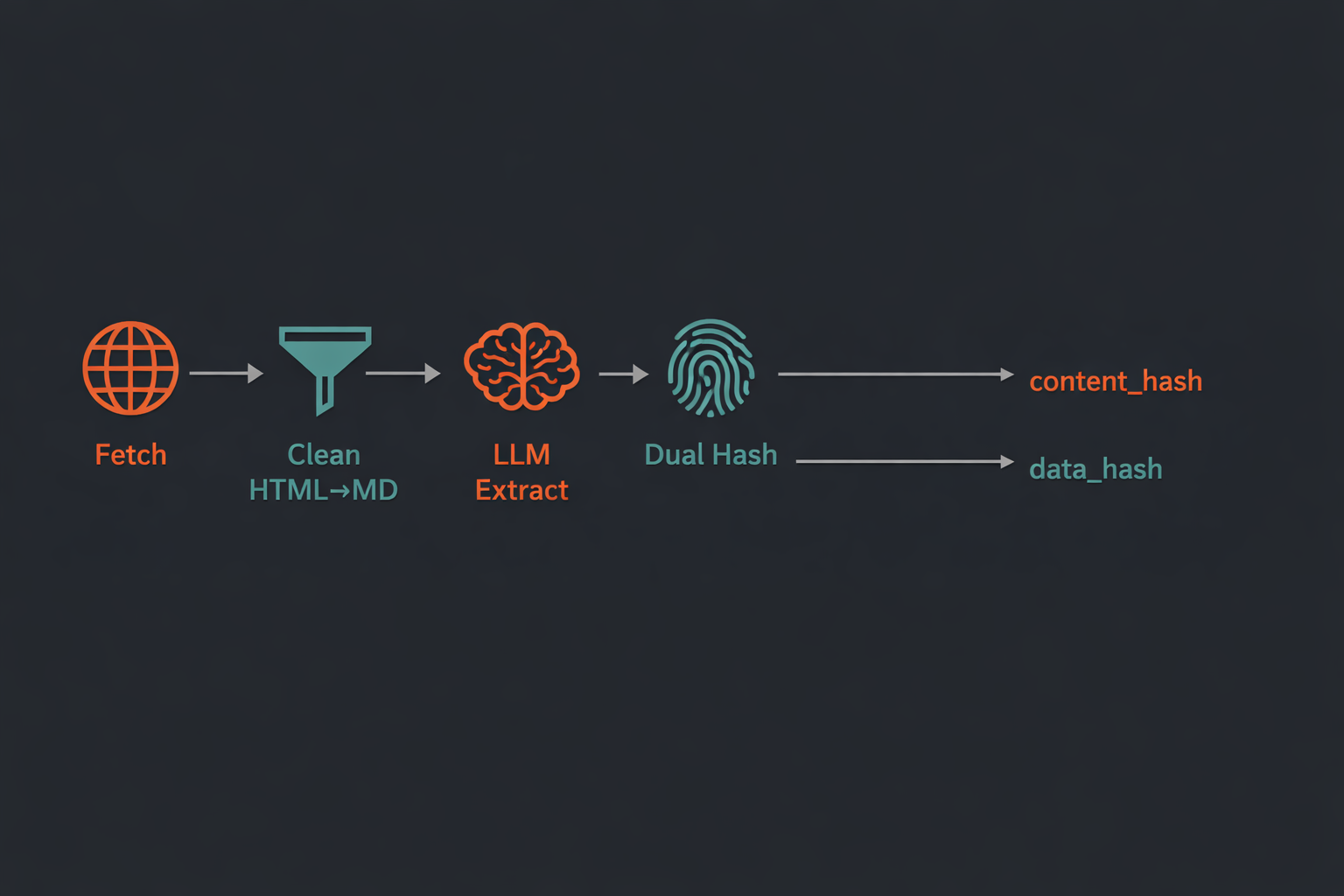
Il sistema a doppio hash è una scelta progettuale deliberata. content_hash traccia se è cambiata la pagina in sé; data_hash traccia se è cambiata l’estrazione strutturata. Questa distinzione è importante: una pagina può cambiare layout, annunci o boilerplate mentre l’LLM continua a estrarre gli stessi dati — content_hash cambia, data_hash resta uguale. Al contrario, se il dato sottostante cambia davvero, si aggiornano entrambi. La pipeline usa il confronto su data_hash per decidere se notificare i consumer downstream.
L’estrazione con LLM usa l’endpoint OpenAI-compatible /chat/completions con response_format: { type: "json_schema" }. Nonostante il nome OpenAiExtractor, funziona con qualunque endpoint compatibile — OpenAI, Gemini (tramite layer di compatibilità OpenAI), Ollama, vLLM, LiteLLM. Configuri ARES_BASE_URL e ARES_MODEL e lo stesso client gestisce il resto.
Fetch di pagine renderizzate in JavaScript
Per HTML statico, Ares usa un ReqwestFetcher standard. Per SPA e siti pesanti in JS, ha un BrowserFetcher che pilota una vera istanza Chromium via Chrome DevTools Protocol. È feature-gated — compila con --features browser per abilitarlo.
Un dettaglio di cui vado fiero: l’auto-detection del binario browser. Su Ubuntu, Chromium è spesso installato via Snap, e il wrapper Snap rimuove flag CLI come --headless fondamentali per l’automazione. Ares cerca prima il binario reale nascosto nel pacchetto Snap:
| |
È il tipo di dettaglio che conta solo quando hai davvero provato a far girare Chromium headless su un sistema Linux reale, e ci ho perso un pomeriggio frustrante.
Sistema di schema
Gli schema sono file JSON Schema versionati, organizzati in directory con un piccolo registro:
| |
Puoi referenziarli per path (schemas/blog/1.0.0.json), per versione (blog@1.0.0) o con alias latest (blog@latest legge registry.json per risolvere la versione corrente). Promuovere una nuova versione a “latest” richiede una singola modifica al file di registro.
| |
Da script a sistema
Dove Ares supera davvero lo script one-off è nell’infrastruttura production attorno all’estrazione core.
Job queue. I job di scraping sono persistiti in PostgreSQL con un lifecycle completo: Pending → Running → Completed/Failed/Cancelled. Crei job via CLI (ares job create) o via REST API (POST /v1/jobs), poi esegui ares worker per processarli. Lo schedule di retry è fisso a [1 minuto, 5 minuti, 30 minuti, 1 ora]:
| |
Ho scelto di hardcodare lo schedule invece di renderlo configurabile per-job. In pratica, la maggior parte dei failure mode (timeout LLM, rate limit, problemi di rete transitori) risponde bene allo stesso pattern di escalation.
Circuit breaker. Una state machine a tre stati (Closed → Open → HalfOpen) protegge da failure a cascata quando la API LLM va giù. La parte interessante è il backoff specifico per rate limit: quando il circuito si apre per risposte HTTP 429, il recovery timeout raddoppia (fino a un massimo di 300 secondi), dando più margine al servizio upstream:
| |
I failure regolari (errori di rete, 500) usano il timeout base di 30 secondi. Questa distinzione evita di trattare tutti i failure allo stesso modo — un rate limit vuol dire “rallenta”, non “il servizio è rotto”.
Throttled fetching. ThrottledFetcher<F> è un wrapper componibile che impone delay minimi per dominio con jitter configurabile. È volutamente opt-in, non automatico — se fai scraping di una sola pagina, non ti serve overhead di throttling; per workload di crawling, invece, wrappi il fetcher e il throttle fa il resto. Il jitter usa una PRNG xorshift64 leggera per evitare di aggiungere rand come dipendenza.
Graceful shutdown. I worker usano un CancellationToken. Su Ctrl+C, il worker termina il job corrente, rilascia eventuali job già presi rimettendoli in queue (Pending) ed esce in modo pulito. I job non si perdono.
REST API. ares-server espone una API basata su Axum con route per job management (POST/GET/DELETE /v1/jobs) e history delle estrazioni (GET /v1/extractions), protetta da autenticazione API key con confronto constant-time per prevenire timing attack. Un endpoint pubblico /health riporta stato servizio e database.
Ceres: harvesting di portali open data
Ceres è un motore di ricerca semantico per portali open-data CKAN. Harvesta metadati di dataset tramite API ufficiali, genera embedding e li indicizza in PostgreSQL con pgvector — rendendo i dataset pubblici ricercabili per significato e non solo per keyword. Il nome viene dalla dea romana del raccolto e del grano.
L’architettura rispecchia Ares: cinque crate (ceres-core, ceres-client, ceres-db, ceres-cli, ceres-server), dependency injection basata su trait e PostgreSQL come layer di persistenza.
Il problema della discoverability
Un cittadino cerca “inquinamento dell’aria” su un portale comunale e non trova nulla — perché il dataset ufficiale si chiama “PM10_monitoring_Q3_2024”. Un ricercatore scrive “popolazione della città” e perde dati demografici perché taggati diversamente. Il problema non è la quantità di dati disponibili; è che la ricerca keyword fallisce sistematicamente quando le persone non conoscono la tassonomia dell’amministrazione.
Ceres risolve questo punto facendo embedding dei metadati dataset (titoli, descrizioni, tag) in uno spazio vettoriale e usando similarità coseno per la ricerca. “Inquinamento dell’aria” trova i dati di monitoraggio PM10 perché i concetti sono semanticamente vicini, anche se le parole non combaciano.
Tre modalità di sync
Questa è la decisione architetturale più importante in Ceres, e impatta direttamente i costi API e il carico sui portali. L’enum SyncPlan definisce tre strategie:
| |
Full recupera la lista di ID dataset, poi scarica ciascun dataset singolarmente — N+1 chiamate API per N dataset. È il fallback sicuro.
FullBulk usa package_search di CKAN con paginazione (rows=1000) per prelevare tutti i dataset in bulk. Per un portale con 10.000 dataset, parliamo di circa 10 chiamate API invece di 10.001. È la strategia preferita per portali grandi.
Incremental usa una Solr filter query (metadata_modified:[{last_sync} TO *]) per prelevare solo i dataset cambiati dall’ultima sync riuscita. In steady-state, questo riduce le chiamate API di ordini di grandezza.
Un dettaglio critico di correttezza: le sync cancellate non avanzano last_successful_sync. Se interrompi un harvest a metà, la successiva sync incrementale riparte dall’ultimo checkpoint completato interamente, evitando che dataset rimangano persi.
Lezioni da portali reali
Queste modalità di sync non sono nate in astratto — sono nate sbattendo contro portali reali.
Irlanda ha una delle istanze CKAN più aggressivamente rate-limited che io abbia incontrato. Il sistema di retry a strati in Ceres (backoff esponenziale per request, cooldown per pagina e circuit breaker sopra tutto) è stato modellato in gran parte tentando di harvestare dati irlandesi senza venire bloccato in modo permanente. La modalità FullBulk è stata essenziale: la strategia Full ID-by-ID avrebbe triggerato rate limit praticamente a ogni altra richiesta.
Svizzera ha evidenziato un problema diverso: i campi metadato multilingua. Un dataset CKAN può avere il titolo come stringa semplice ("Air quality data") o come oggetto JSON ({"en": "Air quality data", "de": "Luftqualitätsdaten", "fr": "Données sur la qualité de l'air"}). Ceres gestisce entrambi con un deserializer custom che risolve la lingua preferita, poi fallback a inglese, poi al primo valore non vuoto. L’hash di contenuto include il codice lingua, quindi cambiare la preferenza lingua forza un re-embedding completo — comportamento corretto, perché il contenuto semantico cambia davvero.
Tokyo è stato il test serio sulla gestione Unicode. I caratteri giapponesi in titoli e descrizioni sono passati nella pipeline senza problemi (le stringhe UTF-8 native di Rust aiutano enormemente), ma è stato uno stress test eccellente per i modelli di embedding — la ricerca semantica cross-lingua è più difficile di quella in una singola lingua.
Australia (data.gov.au) è stato l’harvest mostruoso: oltre 100.000 dataset. Qui FullBulk ha mostrato il suo valore in modo drastico — circa 100 chiamate API paginate invece di 100.001 fetch individuali. La modalità incrementale poi mantiene l’indice aggiornato con carico minimo. Senza queste ottimizzazioni, harvestare l’Australia sarebbe stato impraticabile.
Provider di embedding
A partire dalla v0.2.2, Ceres supporta embedding Gemini e OpenAI, selezionati a runtime tramite la variabile d’ambiente EMBEDDING_PROVIDER.
| |
Il client Gemini usa gemini-embedding-001 con output_dimensionality: 768 — questa è Matryoshka Representation Learning, dove il modello produce un embedding troncato a dimensione più bassa senza retraining. Risultato: riduzione storage 4× rispetto ai 3072 nativi, con perdita minima di qualità nei task di retrieval.
Una misura di sicurezza che ho aggiunto presto: enforcement della dimensione allo startup. Ceres verifica che la dimensione embedding configurata coincida con la colonna pgvector nel database. Se passi da Gemini (768d) a OpenAI (1536d) senza reindicizzare, il check fallisce in modo esplicito invece di produrre silenziosamente score di similarità inutili.
La trait dei provider usa return-position impl Trait (RPITIT), che non è object-safe nell’attuale Rust. Invece di Box<dyn EmbeddingProvider>, Ceres usa un enum concreto EmbeddingProviderEnum per runtime dispatch — workaround pragmatico finché il linguaggio non evolve.
Delta detection
La trait DeltaDetector decide se un dataset necessita rielaborazione:
| |
Il ContentHashDetector di default confronta hash SHA-256 — se il contenuto non è cambiato, l’embedding non viene rigenerato. Su run incrementali contro portali stabili, quasi tutti i dataset restano invariati, ed è qui che nasce il “fino al 99,8% di risparmio sui costi API”. L’input hash include il codice lingua, quindi un dataset il cui titolo inglese cambia ma quello italiano no, in contesto inglese scatena comunque la rielaborazione.
Per rebuild completi — ad esempio quando cambi modello di embedding — AlwaysReprocessDetector è una escape hatch di prima classe che forza il re-embedding totale a prescindere dallo stato hash.
Modalità dry-run
Prima di impegnarti in un harvest full potenzialmente costoso, puoi eseguire la modalità dry-run: i dataset vengono recuperati, gli hash calcolati e gira la delta detection, ma non vengono generati embedding né scritture su database. Questo ti permette di stimare cosa farebbe l’harvest — quanti dataset nuovi, quanti aggiornamenti, quanti invariati — prima di spendere anche un solo credito API.
Export Parquet
Ceres può esportare l’intero indice in file Parquet (Arrow-backed, compressi con Zstd) per consumo downstream — upload su Hugging Face, integrazione in Databricks, o qualsiasi workflow colonnare. L’export include il rilevamento di duplicati cross-portal: i dataset presenti in più portali vengono marcati con un booleano is_duplicate invece di essere rimossi in silenzio, mantenendo trasparenza su dove i dati esistono. Un filtro anti-rumore elimina record con titoli più corti di 5 caratteri o che corrispondono a pattern placeholder.
Dove Ceres e Ares si incontrano
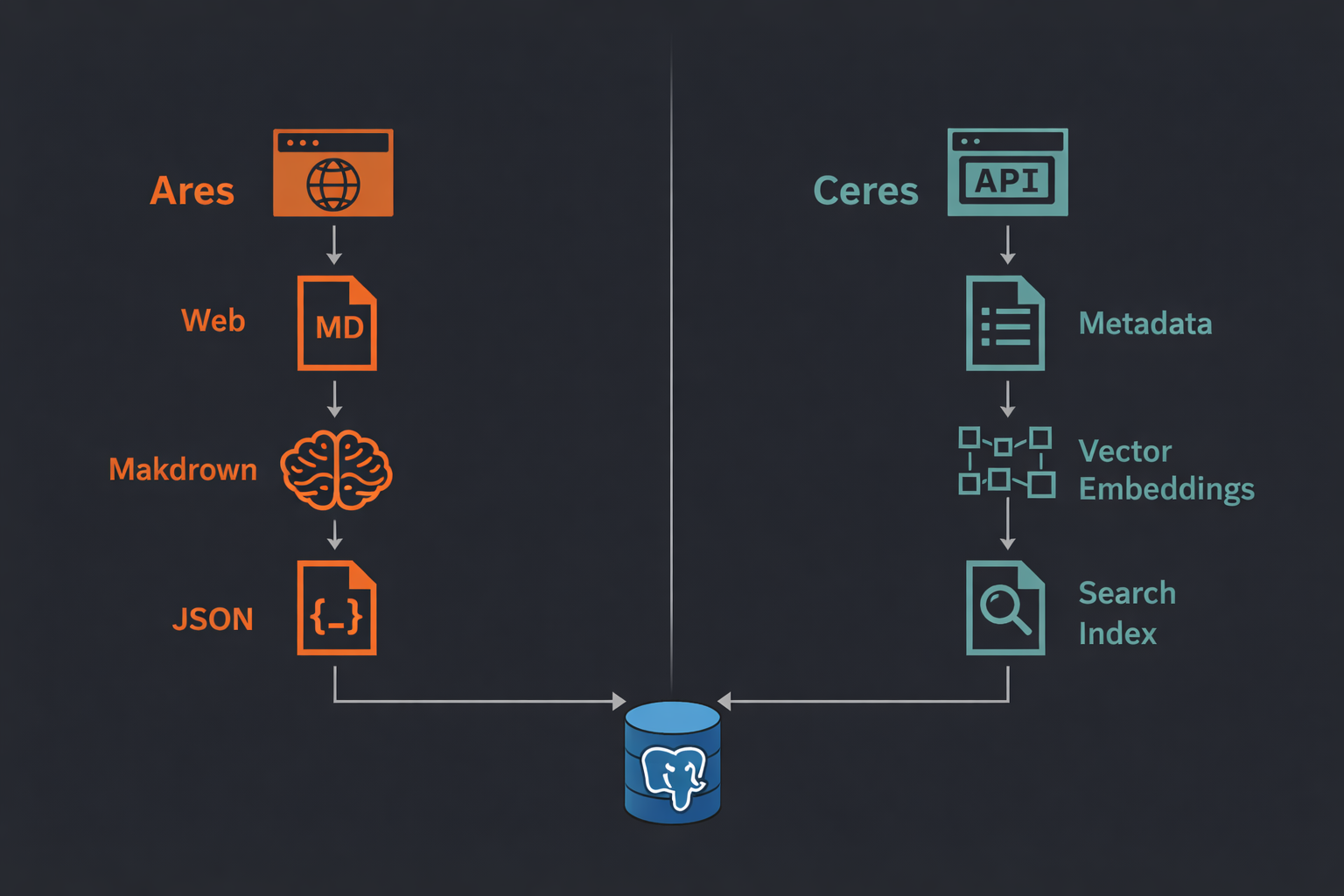
Ceres e Ares condividono la stessa architettura a crate (*-core, *-client, *-db, *-server, *-cli), lo stesso backend PostgreSQL, lo stesso pattern di circuit breaker e la stessa dependency injection basata su trait. Eppure il loro temperamento è completamente diverso.
Ceres opera in collaborazione con i publisher dei dati. Usa API CKAN ufficiali, rispetta i rate limit dei portali con retry a strati e circuit breaker, e il suo indice diventa più ricco nel tempo man mano che si aggiungono nuovi portali. La relazione con la sorgente è cooperativa.
Ares è avversariale in senso ingegneristico. Deve gestire HTML arbitrario, SPA renderizzate in JavaScript, rate limiting da siti che potrebbero non gradire lo scraping e il rumore intrinseco dell’estrazione di struttura da contenuti non strutturati tramite LLM. La relazione con la sorgente è opportunistica.
| Dimensione | Scraping (Ares) | Harvesting (Ceres) |
|---|---|---|
| Interfaccia sorgente | HTML/JS arbitrario | API CKAN ufficiale |
| Metodo di estrazione | LLM + JSON Schema | Metadati strutturati + embedding |
| Change detection | content_hash + data_hash | ContentHashDetector con SHA-256 |
| Efficienza API | 1 chiamata per URL | FullBulk: ~N/1000 chiamate |
| Output | Documenti JSON tipizzati | Indice vettoriale semantico (pgvector) |
Insieme illustrano un principio: quando le sorgenti offrono API stabili e data contract, costruisci harvester. Quando devi passare dall’HTML, costruisci scraper — ma con la stessa disciplina da produzione. Schema, job queue, worker, retry, circuit breaker e graceful shutdown non sono optional. Sono ciò che separa uno strumento utile da uno script che funziona finché non smette.
Cosa ho imparato
Costruire Ares e Ceres uno dopo l’altro ha reso la distinzione harvesting-vs-scraping concreta in un modo che leggere teoria non avrebbe mai fatto. Lo scraping è la tecnica; l’harvesting è ciò che costruisci quando quella tecnica deve girare in produzione ogni giorno, in modo affidabile, con SLA e osservabilità.
L’ecosistema Rust rende questo tipo di pipeline sorprendentemente trattabile. Tokio per l’async, sqlx per l’accesso database, pgvector per similarity search, Axum per HTTP API — si compongono bene, e il type system intercetta classi di bug che in linguaggi dinamici emergerebbero solo a runtime. Le parti più difficili non sono state tecniche: decidere cosa mettere in *-core rispetto a *-client, e resistere alla tentazione di over-engineerizzare prima di avere prove di un requisito reale.
Entrambi i progetti sono in sviluppo attivo. Ares ha in roadmap una modalità di crawling (link discovery a partire dalle extraction). Ceres ha tipi portale Socrata e DCAT già abbozzati nel codebase, in attesa di implementazione. Se uno dei due risuona con quello che stai costruendo, i repository sono aperti — contributi benvenuti.