
Introduzione
Nel mondo della robotica moderna, i dati sono il nuovo petrolio. Ma a differenza del petrolio, i dati robotici sono straordinariamente complessi: stream di sensori ad alta frequenza, point clouds da LiDAR, flussi video compressi, telemetria real-time, e output di algoritmi di percezione che generano terabyte di informazioni ogni giorno di operazione.
Ho scoperto Mosaico per puro caso, mentre curiosavo in giro. Il progetto, nato nel 2025 da Mosaico Labs, è stato recentemente reso open-source e rappresenta un approccio innovativo al problema: una piattaforma dati progettata specificamente per Robotica e Physical AI, con un backend Rust ad alte prestazioni e un SDK Python che si integra nativamente con ROS 2.
Quello che mi ha colpito immediatamente è stata la visione architetturale. Il team fondatore, con esperienza in Autonomous Driving presso aziende come Ambarella, ha costruito Mosaico partendo da problemi reali: come debuggare un sistema robotico quando il bug si manifesta solo dopo ore di operazione? Come cercare pattern specifici in petabyte di dati sensoriali? Come garantire la certificabilità dei dati per standard industriali come ISO 26262?
Dopo aver studiato il codebase e contribuito attivamente al progetto con diverse pull request e proposte nelle discussioni, voglio condividere cosa rende Mosaico interessante e perché rappresenta un caso studio affascinante di integrazione Rust + Python nel dominio dei dati.
Il Problema: Dati Robotica ≠ Dati IT
Prima di addentrarci nell’architettura di Mosaico, è fondamentale comprendere perché i dati robotici richiedono un trattamento diverso rispetto ai tradizionali dati IT.
Caratteristiche Uniche dei Dati Robotici
Alta Frequenza e Sincronizzazione: Un robot moderno può generare dati da decine di sensori simultaneamente. Una camera stereo produce 60 frame al secondo, un LiDAR 10-20 scansioni al secondo, un IMU (Inertial Measurement Unit) fino a 1000 campioni al secondo. Tutti questi stream devono essere sincronizzati temporalmente con precisione sub-millisecondo per ricostruire correttamente lo stato del sistema.
Volumi Massivi di Dati Binari: I dati robotici sono prevalentemente binari e ad alta densità. Un singolo LiDAR Velodyne genera circa 300 MB al minuto di point clouds. Una flotta di 100 robot operativi può produrre petabyte di dati in pochi mesi.
Eterogeneità dei Formati: ROS bag files, protobuf serializzati, formati proprietari di sensori, video H.264/H.265, point clouds in formato PLY o PCD. Ogni componente del sistema robotico ha le sue convenzioni di serializzazione.
Requisiti di Ricostruzione Perfetta: A differenza di analytics tradizionali dove aggregazioni e sampling sono accettabili, nel debugging robotico serve la ricostruzione esatta dello stato del sistema in ogni istante. Un bug che causa una collisione può dipendere da un singolo frame anomalo in un flusso di milioni.
I Limiti degli Approcci Tradizionali
Data Lakes Generici: Soluzioni come Apache Iceberg o Delta Lake eccellono per analytics tabulari, ma non sono progettate per stream sensoriali ad alta frequenza. Mancano primitive per sincronizzazione temporale, replay deterministico, e ricerca semantica su dati non strutturati.
Tool di Visualizzazione: Strumenti come Foxglove o RViz sono eccellenti per visualizzare dati robotici in tempo reale, ma non risolvono il problema dello storage organizzato, della governance, e della ricerca su dataset storici.
Database Time-Series: InfluxDB, TimescaleDB e simili gestiscono bene metriche numeriche, ma non sono ottimizzati per blob binari massivi come point clouds o immagini.
Pipeline ETL Tradizionali: Strumenti come Apache Spark o Flink sono progettati per batch processing o streaming di eventi discreti, non per la ricostruzione deterministica di stream sensoriali continui.
Il Gap da Colmare
Mosaico nasce per colmare questo gap: una piattaforma che combina le capacità di un data lake moderno (storage scalabile, metadata management, governance) con primitive specifiche per robotica (sincronizzazione temporale, replay deterministico, ricerca semantica su dati sensoriali).
Architettura Mosaico
L’architettura di Mosaico segue un pattern client-server che separa chiaramente le responsabilità tra un daemon Rust ad alte prestazioni e un SDK Python pensato per l’ergonomia degli sviluppatori.
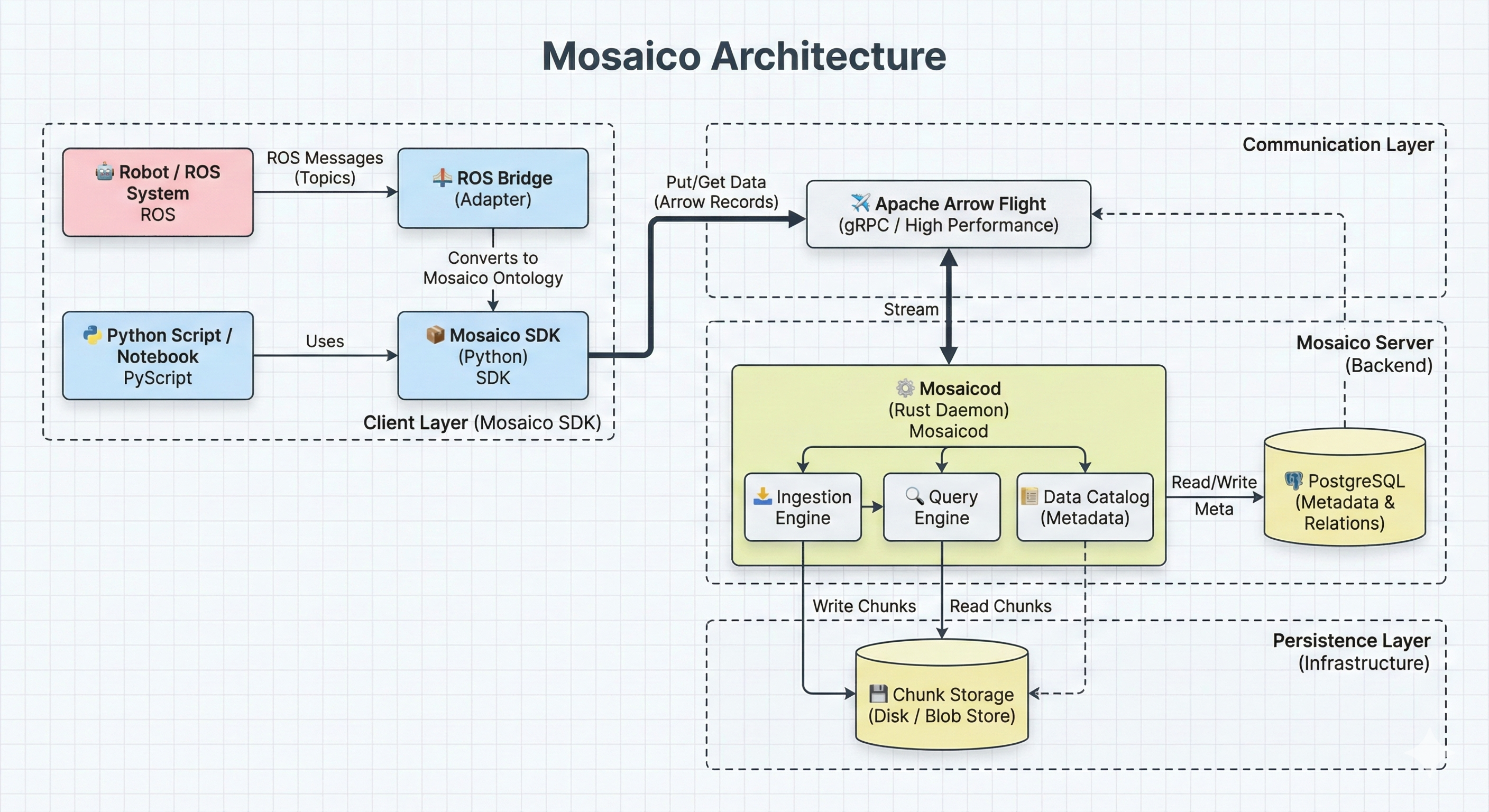 Schema dell’architettura client-server di Mosaico: il daemon Rust (mosaicod) gestisce storage, compressione e metadata, mentre i client Python comunicano via Apache Arrow Flight
Schema dell’architettura client-server di Mosaico: il daemon Rust (mosaicod) gestisce storage, compressione e metadata, mentre i client Python comunicano via Apache Arrow Flight
mosaicod: Il Daemon Rust
Il cuore di Mosaico è mosaicod, un daemon scritto interamente in Rust che gestisce tutte le operazioni pesanti:
Storage e Compressione: mosaicod riceve dati dai client, applica compressione ottimizzata per tipo di dato (diversi codec per immagini, point clouds, telemetria), e organizza lo storage in modo efficiente.
Metadata Management: Utilizza PostgreSQL come backend per i metadati, con query SQL verificate a compile-time tramite sqlx. Questo garantisce type safety end-to-end: se una query è mal formata, il compilatore Rust la rifiuta prima ancora che il codice venga eseguito.
Indicizzazione Semantica: mosaicod estrae automaticamente metadati semantici dai dati grezzi (coordinate GPS, timestamp, classificazioni) e li indicizza per ricerche efficienti.
Protocol Server: Espone un’interfaccia basata su Apache Arrow Flight per comunicazione ad alta performance con i client.
| |
Python SDK: Ergonomia e Integrazione
Il Python SDK (mosaico-sdk-py) fornisce un’interfaccia pulita per interagire con mosaicod:
Astrazione della Comunicazione: Il SDK nasconde la complessità del protocollo Arrow Flight, esponendo API Pythonic per lettura e scrittura.
Integrazione ROS 2: Converter nativi per i tipi di messaggio ROS 2 più comuni, permettendo di caricare sequenze direttamente da topic ROS.
Compatibilità Ecosystem: Interoperabilità con PyArrow, NumPy, e framework ML come PyTorch e TensorFlow.
L’esempio seguente illustra una query alla piattaforma e mostra come scaricare i dati di una delle sequenze restituite, nonché come ottenere il data stream sincronizzato:
| |
L’SDK esegue automaticamente un k-way merge sort lato client per garantire che i messaggi dei sensori siano restituiti nel corretto ordine temporale. Il flusso di dati non viene scaricato tutto in una volta, ma tramite una strategia di buffering intelligente, attraverso batch di memoria limitata, che vengono sostituiti automaticamente da nuovi batch man mano che i dati vengono elaborati.
I Tre Pilastri: Ontology, Topic, Sequence
L’architettura di Mosaico si basa su tre concetti fondamentali che strutturano l’organizzazione dei dati:
Ontology: Rappresentazione semantica dei tipi di dato. L’ontologia definisce cosa significa ogni tipo di sensore, detection, o mappa semantica. Non è solo uno schema di validazione, ma un vocabolario condiviso che permette ricerche cross-dataset.
Topic: Un Topic rappresenta una sorgente di dati specifica (es. “front_camera”, “lidar_top”, “gps_position”) con la sua ontologia associata e configurazione di storage.
Sequence: Una Sequenza è una raccolta di Topic logicamente correlati. Ad esempio, una sessione di registrazione di un robot, come un ROS bag, è una Sequenza che contiene letture provenienti da vari sensori, dove ogni sensore (come Lidar, GPS o accelerometro) è rappresentato da un Topic.
Value Proposition: Oltre lo Storage
Mosaico non è solo un sistema di storage. La sua architettura abilita capacità che vanno ben oltre il semplice salvataggio di dati.
Data-Oriented Debugging
Il debugging tradizionale in robotica si basa su log testuali e visualizzazione real-time. Quando un robot fallisce una missione, gli ingegneri devono ricostruire mentalmente cosa è successo analizzando log frammentati.
Nella roadmap del progetto, uno degli sviluppi futuri più significativi riguarda l’introduzione del data-oriented debugging, una funzionalità fondamentale per migliorare il processo di sviluppo di algoritmi robotici:
- Checkpoint Completi: Invece di loggare solo eventi significativi, Mosaico permetterà di salvare lo stato completo di ogni componente della pipeline a intervalli regolari: preprocessing dei sensori, output di filtri di stima, checkpoint intermedi degli algoritmi—tutto viene preservato.
- Replay Deterministico: Con tutti gli stati intermedi salvati, sarà possibile “riavvolgere” l’esecuzione del robot a qualsiasi punto nel tempo e ispezionare lo stato esatto del sistema.
- Root Cause Analysis: Quando si identifica un’anomalia (es. una detection errata), si potrà tracciare all’indietro attraverso la pipeline per identificare il punto esatto dove l’errore si è originato: era il sensore, il preprocessing, o l’algoritmo di detection?
Già dalla versione v0.1, è possibile estrarre lo stream di dati di una sequenza o di un singolo topic, specificando opzionalmente gli intervalli temporali di interesse. Questo approccio consente di ridurre al minimo la quantità di dati scambiati, evitando il trasferimento di informazioni superflue:
| |
Semantic Data Platform
L’ontologia di Mosaico non è solo uno schema di validazione—è un’infrastruttura semantica che abilita operazioni intelligenti sui dati.
Standardizzazione Cross-Team: In organizzazioni con più team robotici, l’ontologia fornisce un vocabolario comune. Un “pedestrian_detection” significa la stessa cosa per il team perception e per il team planning.
Metadata Extraction Automatica: Mosaico estrae automaticamente metadati semantici dai dati grezzi. Coordinate GPS vengono indicizzate per ricerche geospaziali, timestamp per query temporali, classificazioni per ricerche categoriche.
Storage Optimization per Tipo: L’ontologia mappa ogni tipo di dato al formato di storage ottimale. Point clouds usano compressione specializzata, immagini usano codec video, telemetria numerica usa formati colonnari.
Versioning dei Modelli Dati: L’ontologia supporta evoluzione versionata. Quando il formato di un sensore cambia, la nuova versione coesiste con la vecchia, permettendo query che spannano entrambe.
Roadmap: Multimodal Search
Con petabyte di dati robotici, trovare informazioni specifiche diventa impossibile con approcci tradizionali basati su filename o tag manuali.
Mosaico abilita la ricerca multimodale su dati temporali e metadati (relativi a sequenze e topic). Il team di sviluppo sta progettando architetture di ricerca sempre più complesse ed efficienti, che consentiranno query geospaziali, basate su embedding e su linguaggio naturale, ad esempio: «Trova tutte le sequenze in cui il robot ha tentato di afferrare una mela rossa».
Certifiability
Per applicazioni industriali (automotive, aerospace, medical), i dati devono rispettare rigorosi standard di certificazione. Nella roadmap del progetto, una componente strategica è dedicata alla certificabilità delle pipeline algoritmiche, che sarà progressivamente estesa fino a coprire l’intero ciclo di vita del dato.
Data Lineage Completo (in evoluzione): Mosaico è progettato per tracciare in modo esaustivo la provenienza di ogni dato—sensore, versione del firmware, algoritmo di preprocessing—con l’obiettivo di offrire una tracciabilità completa e verificabile.
Validazione Dichiarativa (in fase di sviluppo): Le regole di qualità potranno essere definite a livello di ontologia e validate automaticamente durante la fase di ingestione dei dati.
Audit Trail (roadmap): Ogni operazione sui dati sarà registrata per garantire la conformità a standard di settore come ISO 26262 (automotive), EASA (aerospace) e MISRA.
Perché Rust + Python (Non FFI)
Una delle scelte architetturali più interessanti di Mosaico è l’uso di un pattern client-server invece dei più comuni binding FFI (Foreign Function Interface) tramite PyO3 o Maturin.
Il Pattern Tradizionale: PyO3/FFI
L’approccio più comune per integrare Rust e Python è compilare il codice Rust come libreria nativa e esporla a Python tramite PyO3:
| |
Questo funziona bene per operazioni stateless e CPU-bound, ma presenta limitazioni per piattaforme dati complesse.
Perché Mosaico Ha Scelto Client-Server
Process Isolation: Con un daemon separato, crash nel backend Rust non terminano l’applicazione Python. Questo è critico per sistemi robotici dove la stabilità è fondamentale.
Multi-Tenancy: Un singolo daemon mosaicod può servire multipli client Python simultaneamente, condividendo risorse (connection pool, cache, indici) efficientemente.
Containerization: L’architettura client-server si integra naturalmente con deployment containerizzati. Il daemon può girare in un container dedicato con risorse isolate, mentre i client Python vivono in container separati.
Scalabilità Indipendente: Backend e client possono scalare indipendentemente. Puoi avere un daemon mosaicod su hardware potente che serve decine di client leggeri.
Flessibilità Linguistica: Con un protocollo ben definito (Arrow Flight), è facile aggiungere client in altri linguaggi (Go, C++, Rust nativo) senza modificare il backend.
Team Scaling: Specialisti Rust si concentrano sul backend ad alte performance, specialisti Python sull’SDK e integrazioni. I team possono lavorare in parallelo con interfacce chiare.
Evolution: Il backend può evolvere internamente (nuovi algoritmi di compressione, ottimizzazioni di storage) senza rompere la compatibilità con client esistenti, finché il protocollo rimane stabile.
Trade-offs
Questa architettura non è senza costi:
Latenza di Rete: Ogni chiamata attraversa il network stack, aggiungendo ~0.5-1ms di overhead rispetto a chiamate FFI dirette (~microseconds).
Complessità Operazionale: Serve gestire un daemon in più, con il suo lifecycle, monitoring, e configurazione.
Serializzazione: I dati devono essere serializzati/deserializzati per attraversare il confine processo, consumando CPU.
Per Mosaico, questi trade-off sono accettabili perché le operazioni tipiche (scrittura di sequenze sensoriali, query su dataset) sono già nell’ordine di decine/centinaia di millisecondi, rendendo l’overhead di rete trascurabile.
Il Mio Contributo al Progetto
Il mio percorso con Mosaico è iniziato come spesso accade nell’open source: con la documentazione. Link non funzionanti, istruzioni inconsistenti—niente di drammatico, ma il è tipo di miglioramento a basso impatto sempre gradito nell’Open Source. Da lì, nelle ultime tre settimane, il coinvolgimento è cresciuto naturalmente tra PR, issue, discussioni e RFC.
Tra i contributi più significativi: l’issue #18, dove ho identificato un problema di performance serio nel calcolo della dimensione ottimale dei batch—O(N) richieste HEAD sequenziali verso S3, ~50 secondi di attesa con 1.000 chunk. La soluzione? Una singola query SQL O(1). E la PR #40, nata da una discussione nell’issue #27: come permettere ai client di scoprire i topic disponibili? Ho proposto la convenzione Arrow Flight—path vuoto restituisce l’elenco completo—e poi ho implementato l’endpoint. La mia prima feature “vera”.
Ma l’aneddoto che racconta meglio l’esperienza è la PR #52. Erano le 10 di sera, stavo analizzando SequenceTopicGroups::merge e ho notato una complessità O(n×m) che poteva diventare O(n+m) con una HashMap. Ho scritto i benchmark, aperto la PR, e il maintainer ha risposto con un punto che non avevo considerato: per dataset piccoli (< 100 sequenze), la ricerca lineare può battere la HashMap grazie alla cache locality. Ne è nata una discussione tecnica genuina—sort + binary search come compromesso, crossover point attorno a 50-100 elementi. La PR è ancora aperta ed io stesso ho fatto un passo indietro sull’implementazione, ma continueremo a provare! Non esiste vero fallimento nella programmazione, se non quello di non tentare. E’ esattamente questo tipo di scambio che rende l’open source stimolante: non stai solo scrivendo codice, stai imparando.
Attualmente sto portando avanti una RFC (issue #45) per l’integrazione con Data Contract Engine—definire contratti espliciti sui dati e validarli durante l’ingestione. La proposta ha generato interesse, e vedremo dove porta.
Review in 24-48 ore, commenti costruttivi, apertura verso proposte architetturali. Per chi vuole iniziare: documentazione, ergonomia, piccoli fix. Non perché siano contributi “minori”, ma perché ti permettono di capire il codebase e costruire la fiducia per proposte più ambiziose.
Panorama Competitivo
Mosaico non opera in un vuoto. Esistono altri strumenti che affrontano parti del problema dei dati robotici.
Foxglove
Focus: Visualization e observability real-time
Punti di Forza: Eccellente visualizzazione multimodale, supporto per ROS bag, interfaccia web moderna, streaming efficiente.
Limitazioni rispetto a Mosaico: Foxglove è primariamente un tool di visualizzazione, non una piattaforma di storage e governance. Non offre le primitive per data-oriented debugging su dataset storici o ricerca semantica su petabyte.
Rerun
Focus: Multimodal data stack per ML e robotica
Punti di Forza: SDK elegante, ottimizzato per workflow ML, supporto per diversi tipi di dati (point clouds, tensori, immagini).
Limitazioni rispetto a Mosaico: Rerun si concentra sulla visualizzazione e logging per sviluppo. Non ha le capacità enterprise di governance, certificabilità, e storage a scala petabyte.
ARES
Focus: Robot evaluation via annotation e curation
Punti di Forza: Workflow strutturati per annotazione dati, metriche di valutazione robot, integrazione con pipeline ML.
Limitazioni rispetto a Mosaico: ARES è focalizzato sulla fase di evaluation/annotation, non sull’intera lifecycle dei dati dalla raccolta al debugging.
Differenziatori di Mosaico
| Aspetto | Mosaico | Foxglove | Rerun | ARES |
|---|---|---|---|---|
| Storage petabyte-scale | ✅ | ❌ | ❌ | ❌ |
| Data-oriented debugging | ✅ | Parziale | ❌ | ❌ |
| Ontologia semantica | ✅ | ❌ | Parziale | ❌ |
| Certificabilità | ✅ | ❌ | ❌ | ❌ |
| Visualizzazione real-time | Parziale | ✅ | ✅ | ✅ |
| ROS 2 integration | ✅ | ✅ | ✅ | ✅ |
Mosaico non compete direttamente con questi tool—può integrarsi con essi. I dati gestiti da Mosaico possono essere visualizzati in Foxglove, le sequence possono alimentare pipeline Rerun per sviluppo, e i dataset curati possono essere esportati verso ARES per annotation.
Come Iniziare con Mosaico
Se vuoi provare Mosaico, il modo più semplice è usare Docker Compose.
Quickstart con Docker
| |
Questo avvia:
mosaicod: Il daemon Rust sulla porta 50051 (Arrow Flight)- PostgreSQL: Backend per i metadati
- (Opzionale) MinIO: Object storage S3-compatibile per i dati
Primo Utilizzo con Python SDK
| |
Esempio: Ingestione da ROS 2
L’esempio seguente mostra come fare upload di una sequenza nativa ROS2 (formato .db3) su Mosaico, attraverso il ros-bridge fornito dalla libreria:
| |
Documentazione e Risorse
- Repository: https://github.com/mosaico-labs/mosaico
- Core Concepts:
CORE_CONCEPTS.mdnel repository spiega i tre pilastri (Ontology, Topic, Sequence) - SDK Python: La directory
mosaico-sdk-py/contiene esempi e documentazione dell’API - mosaicod: La directory
mosaicod/contiene la documentazione del daemon Rust
Conclusione
Mosaico rappresenta un approccio innovativo al problema dei dati robotici. Invece di adattare strumenti generici di data engineering, il progetto parte dalle esigenze specifiche della robotica: sincronizzazione temporale, replay deterministico, debugging post-mission, e certificabilità.
L’architettura Rust + Python con pattern client-server è una scelta pragmatica che bilancia performance, isolamento, e ergonomia. Il daemon Rust gestisce le operazioni pesanti con garanzie di memory safety, mentre il SDK Python offre l’integrazione seamless con l’ecosistema ROS 2 e ML.
Il progetto è ancora giovane—open-sourced a dicembre 2025—ma ha già dimostrato momentum significativo. La mia esperienza di contribuzione è stata positiva: il team è aperto a proposte, il processo di review è costruttivo, e c’è spazio per contribuzioni sia incrementali (fix, ottimizzazioni) che architetturali (come la mia RFC su Data Contracts).
Per chi lavora nel dominio robotica o Physical AI e si trova a gestire volumi crescenti di dati sensoriali, Mosaico merita attenzione. Non sostituisce i tool di visualizzazione esistenti, ma li complementa fornendo l’infrastruttura di storage, governance, e debugging che manca nell’ecosistema attuale.
Call to Action
Se sei interessato a contribuire, alcune aree dove il progetto ha bisogno di aiuto:
Ontologie Specializzate: Definire ontologie per nuovi tipi di sensori o domini applicativi (agricultural robots, underwater vehicles, humanoids).
Integration Testing: Più coverage per scenari edge case e integrazione con diversi setup ROS 2.
Documentazione: Guide pratiche, tutorial, e case study di utilizzo.
Client SDK Alternativi: Implementazioni in Go, C++, o Rust nativo per ambienti dove Python non è disponibile.
Il futuro della robotica è data-driven. Strumenti come Mosaico sono fondamentali per trasformare i petabyte di dati sensoriali da peso morto a risorsa strategica per debugging, training, e continuous improvement dei sistemi robotici.
Repository: https://github.com/mosaico-labs/mosaico
I Miei Contributi:
- PR #56, #51, #40, #37, #33, #26, #23, #20, #15
- RFC #45: Data Contract Validation
- Issue #18, #27 e discussioni varie
*Code snippets gentilmente curati da Francesco Di Corato, CSO@ Mosaico
Un ringraziamento al team di Mosaico Labs per l’accoglienza, le review costruttive, e la disponibilità a discutere proposte architetturali. L’open source funziona quando c’è apertura verso i contributor—e qui l’ho trovata.